A workshop in Data-Centric AI is being held at NeurIPS, announced Andrew Ng of DeepLearning.AI. A number of the best academic papers related to data-centric AI will be presented at the workshop. Research papers can be submitted by academic researchers and practitioners until September 30, 2021.

Aroyo, Coleman, Diamos, Janapa Reddi, Vanschoren, and Zhou are all on the organizing committee. Also on the committee is Lora Aroyo of Google Research and Google’s machine learning product manager, Sharon Zhou.
Data-Centric AI: What is it?
It represents a recent shift from model-centric to data-centric AI, in which models are trained and evaluated using actual data. ML systems require an infrastructure to manage data and tools to handle data types. DCAI aims to fill these gaps. In addition, it aims to offer high productivity and efficient open data engineering tools for seamless and cost-effective dataset collection, maintenance, and evaluation.
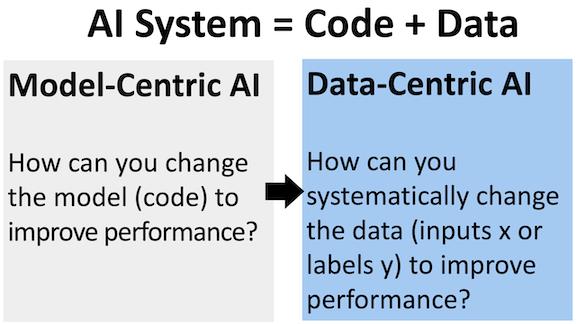
DCAI aims to cultivate a vibrant interdisciplinary community of researchers and address practical data problems through this event. In addition to data collection and generation, data labeling, data preprocessing, and data augmentation, data quality evaluation, and data governance, there are problems associated with data. They hope to bring the ML community together to bridge gaps in many of these areas, most of which are still in the early stages.
Submissions are being sought
Datasets used by AI systems are often created and used artisanally – with much painstaking work and expense. Data engineering tools that are high-productivity and efficient are not readily available for the ML community. Even today, the democratisation of data engineering and evaluation, as well as improving efficiency of use and reuse, remain core challenges in the creation and iteration of data.
“If 80 per cent of machine learning work is data preparation, then ensuring data quality is the most important work of an ML team and therefore a vital research area,” said the NeurIPS DSAI team. A compass and fuel for AI-based software systems, human-tagged data has become increasingly important, they added. Innovative approaches have mainly focused on models and code, they said.
Over the last few years, however, there has been an increased emphasis on obtaining and improving datasets at a faster speed and for a lower cost, which has impacted quality. These involve work on Response-based Learning for Grounded Machine Translation, Crowdsourcing with Fairness, Diversity, and Budget Constraints, Excavating AI, Data Excellence: Better Data for Better AI, State of the Art: Reproducibility in Artificial Intelligence, among others.
In their report, the NeurIPS DCAI team said that there needs to be a framework for excellence in data engineering, noting that data characteristics like consistent, reproducible, reliable, valid, and fidelity are often overlooked when releasing a dataset into the market. The team plans to discuss examples, case studies, and other methods for improving the data collection process during this event.
Data-centric AI researchers at NeurIPS said it is crucial to establish an active community that supports the definition of core problems and creates quantitative measures of progress in machine learning through data quality tasks.
Subjects
The following topics, which include but are not limited to: can be submitted by interested candidates:
The following new data sets were released:
- Speaks, sees, manufactures, medically, recommends/personalizes
- Science
Tool-and-methodologies that can be used to:
- Accelerate the process of sourcing high-quality data by quantifying it and speeding it up
- Consistently label data, for instance by using consensus labels
- Enhance the quality of data in a systematic way.
- Using low-quality training resources, such as forced alignment in speech recognition, automatically generate high quality supervised learning training data
- Data samples should be uniform and noise-free, or existing data should be cleaned up to remove labeling noise and inconsistencies
- Add vocabulary words, languages, and make high-level edits in large datasets.
- The use of public resources for finding suitable licenses for datasets
- Creating small data set training datasets for big data problems dealing with rare classes
- Update datasets with feedback from production systems in a timely manner
- Understand dataset coverage of important classes and editing them to cover newly identified important cases
- Import dataset by allowing easy combination and composition of existing datasets
- Export dataset by making the data consumable for models and interface with model training and inference systems such as web dataset
- Enable composition of dataset tools like MLCube, Docker, Airflow
Improvement of label efficiency and algorithms for working with limited labelled data
- Identifying the most valuable examples to label using active learning and core-set selection techniques
- Methods that enable limited labelled data to be used to their fullest potential include semi-supervised learning, few-shot learning, as well as weak supervision
- Learning to develop powerful representations for a variety of downstream tasks without sufficient labelled data.
- Innovative, drift-detecting technology for spotting more data that needs to be labelled
The development of AI must be responsible:
- Evaluation and analysis of datasets, algorithms, and models for fairness, bias, and diversity
- Tools for the design and evaluation of ‘green AI hardware-software systems’
- Systems and methods that scale and are reliable
- Private, secure ML training tools, methods, and techniques
- Work on reproducible artificial intelligence (data cards, models, etc.).
Submitting papers: instructions
- In addition to submitting short papers (1 or 2 pages), researchers can submit long papers (4 pages), which can cover one or more of the topics listed in the call
- Formatting papers should follow NeurIPS 2021 guidelines
- Program committee members will review papers
- Workshop lighting talks will be given by accepted papers
Timeline
- The deadline for early submissions is September 17, 2021
- 30 September 2021: Deadline for submissions
- 22 October 2021: Notification of acceptance
- 14 December 2021: Workshop



