
Artificial intelligence is mostly a math problem. We finally have enough data and processing capacity to make full advantage of deep neural networks, a type of AI that learns to discover patterns in data, when they began to surpass standard algorithms 10 years ago.
Today’s neural networks are even more data and processing power hungry. Training them necessitates fine-tuning the values of millions, if not billions, of parameters that describe these networks and represent the strength of artificial neuron connections. The goal is to discover almost perfect values for them, which is known as optimization, but training the networks to get there is difficult. Petar Velikovi, a staff research scientist at DeepMind in London, said, “Training could take days, weeks, or even months.”
That could change in the near future. Boris Knyazev and colleagues from the University of Guelph in Ontario created and trained a “hypernetwork”—a kind of overlord for other neural networks—that could help speed up the training process. The hypernetwork forecasts the parameters for a fresh, untrained deep neural network tailored for some task in fractions of a second, potentially eliminating the need for training. The finding may have deeper theoretical ramifications because the hypernetwork learns the extremely intricate patterns in the designs of deep neural networks.
For the time being, the hypernetwork functions admirably in some situations, but there is still potential for improvement, which is understandable given the scope of the problem. “This will have a really big impact across the board for machine learning,” Velikovi said if they can solve it.
Getting Excited
Currently, versions of a technique known as stochastic gradient descent are the best approaches for training and improving deep neural networks (SGD). The goal of training is to reduce the network’s errors on a certain job, such as image recognition. To change the network’s parameters and eliminate errors, or loss, an SGD algorithm churns through a large amount of labelled data. Gradient descent is an iterative process of descending from high loss function values to a minimum value that indicates good enough (or even the best feasible) parameter values.
However, this method is only effective if you have a network to optimise. Engineers must rely on intuition and rules of thumb to create the initial neural network, which is often made up of numerous layers of artificial neurons that lead from an input to an output. The number of layers of neurons, the number of neurons per layer, and other factors can all affect the architecture.

In theory, one could start with a large number of architectures, optimise each one, and then choose the best. “However, training takes a significant amount of time,” Mengye Ren, now a visiting researcher at Google Brain, explained. It would be impossible to train and test every network architecture contender. “It doesn’t scale well, especially when millions of different designs are taken into account.”
Ren, his former University of Toronto colleague Chris Zhang, and their adviser Raquel Urtasun decided to take a different strategy in 2018. Given a series of potential architectures, they created a graph hypernetwork (GHN) to discover the optimum deep neural network architecture to accomplish a job.
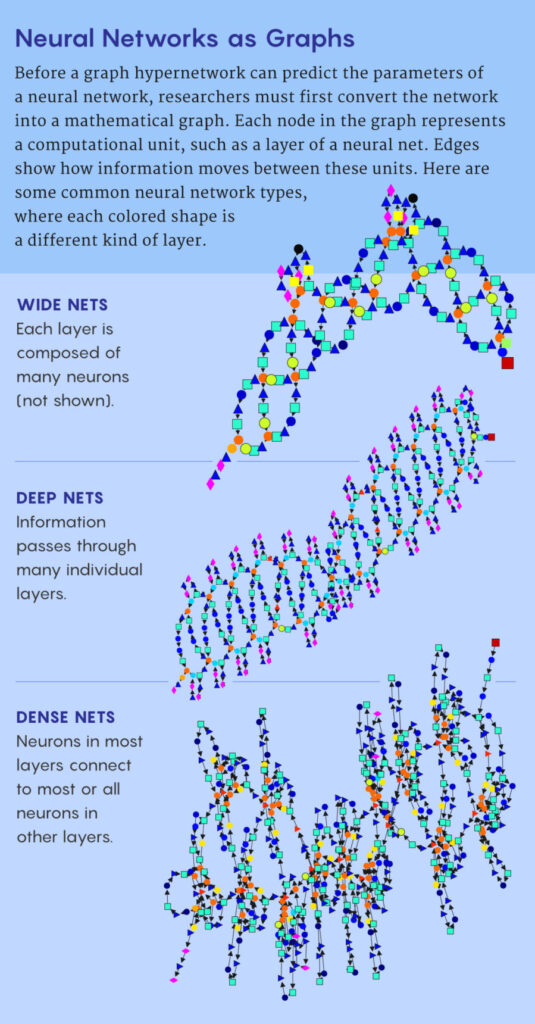
Their strategy is summed up in the name. The term “graph” alludes to the idea that a deep neural network’s design can be compared to a mathematical graph, which consists of a collection of points, or nodes, connected by lines, or edges. The nodes represent computing units (often a whole layer of a neural network), and the edges indicate the connections between these units.
This is how it goes. Any architecture that needs to be optimised (let’s call it the candidate) is the starting point for a graph hypernetwork. It then tries its hardest to anticipate the candidate’s optimal parameters. The team then calibrates the parameters of a real neural network to the predicted values before putting it to the test on a specific job. Ren’s team demonstrated how to utilise this strategy to rank candidate architectures and choose the best one.
Knyazev and his colleagues realised they could build on the graph hypernetwork concept when they came across it. The team demonstrates how to use GHNs not only to determine the best architecture from a set of samples, but also to predict the parameters for the best network so that it performs well in an absolute sense in their new study. In cases where the best isn’t good enough, gradient descent can be used to train the network further.
“It’s a pretty sturdy piece of paper.” The new approach “has a lot more exploration than what we accomplished,” Ren added. “They work extremely hard to improve the overall performance, which is fantastic to witness.”
The Trainer’s Education

Knyazev and his colleagues dubbed their hypernetwork GHN-2, and it improves on two key characteristics of Ren and colleagues’ graph hypernetwork.
First, they used Ren’s method of representing a neural network’s architecture as a graph. Each node in the graph represents a subset of neurons that do a certain sort of processing. The graph’s edges indicate the flow of data from node to node, from input to output.
The way of training the hypernetwork to produce predictions for new candidate designs was the second idea they came up with. This necessitates the use of two more neural networks. The first allows computations on the original candidate graph, which results in changes to information associated with each node, and the second takes the updated nodes as input and predicts the parameters for the candidate neural network’s corresponding computational units. These two networks each have their own set of parameters that must be improved before the hypernetwork can forecast parameter values appropriately.
You’ll need training data for this, which is a random sampling of possible artificial neural network (ANN) topologies in this case. You start with a graph for each architecture in the sample, then use a graph hypernetwork to predict parameters and initialise the candidate ANN with the predicted parameters. The ANN then performs a specified task, such as image recognition. You calculate the ANN’s loss and then adjust the parameters of the hypernetwork that created the forecast in the first place, rather than updating the ANN’s parameters to make a better prediction. This allows the hypernetwork to improve its performance the following time around. Iterate over every image in a labelled training data set of images and every ANN in a random sample of architectures, minimising the loss at each step until it can no longer perform better. After a while, you’ll have a trained hypernetwork.
Because Ren’s team didn’t publish their source code, Knyazev’s team used these concepts and created their own programme from the ground up. Then it was improved upon by Knyazev and his colleagues. To begin, they identified 15 different types of nodes that may be used to create practically any modern deep neural network. They also developed a number of advancements in order to improve prediction accuracy.
Most importantly, Knyazev and colleagues constructed a unique data set of 1 million different structures to ensure that GHN-2 learns to forecast parameters for a wide range of target neural network architectures. “To train our model, we constructed as many different random designs as possible,” Knyazev explained.
As a result, the prediction abilities of GHN-2 are more likely to translate effectively to unknown target architectures. “For example, they can account for all of the typical state-of-the-art designs that people use,” said Thomas Kipf, a research scientist with Google Research’s Brain Team in Amsterdam. “That is a significant contribution.”
Exceptional Results
Of course, putting GHN-2 to the test was the true test. After training it to predict parameters for a specific goal, such as categorising photos in a specific data set, Knyazev and his team put it to the test to predict parameters for any random candidate architecture. This new contender could have traits that are comparable to those of the million structures in the training data set, or it could be unique — an outlier. The target architecture is said to be in distribution in the first scenario and out of distribution in the second. Deep neural networks frequently fail to predict the latter, therefore putting GHN-2 to the test on such data was crucial.
The scientists used a fully trained GHN-2 to forecast parameters for 500 random target network designs that had never been seen before. The 500 networks were then matched against the identical networks trained using stochastic gradient descent, with their parameters set to the predicted values. The new hypernetwork was able to compete with hundreds of iterations of SGD, and in some cases outperformed them, albeit the results were mixed.
The average accuracy of GHN-2 on in-distribution designs was 66.9% for a data set known as CIFAR-10, which was close to the 69.2 percent average accuracy produced by networks trained using 2,500 iterations of SGD. GHN-2 performed surprisingly well for out-of-distribution architectures, reaching roughly 60% accuracy. It produced a good 58.6% accuracy for a well-known deep neural network architecture called ResNet-50 in particular. “Given that ResNet-50 is around 20 times larger than our normal training architecture, generalisation to ResNet-50 is surprisingly good,” Knyazev stated at NeurIPS 2021, the field’s flagship symposium.

With ImageNet, a much larger data set, GHN-2 didn’t fare quite as well: It was just approximately 27.2 percent correct on average. Nonetheless, this compares favourably to the average accuracy of 25.6 percent achieved by the same networks trained with 5,000 SGD steps. (Of course, if you keep using SGD, you can finally achieve 95 percent accuracy at a significant expense.) Most importantly, GHN-2 predicted ImageNet parameters in less than a second, whereas SGD took 10,000 times longer on their graphical processing unit to achieve the same performance as the predicted parameters (the current workhorse of deep neural network training).
“The results are definitely super impressive,” Veličković said. “They basically cut down the energy costs significantly.”
When GHN-2 selects the best neural network for a job from a set of designs, and that best option isn’t good enough, the winner is at least partially trained and can be further refined. Instead of unleashing SGD on a network with random parameter values, the predictions of GHN-2 can be used as a starting point. “We basically simulate pre-training,” Knyazev explained.
GHN-2 and Beyond
Despite these achievements, Knyazev believes that the machine learning community would initially be sceptical of graph hypernetworks. He compares it to the resistance that deep neural networks faced before to 2012. Machine learning experts at the time favoured hand-crafted algorithms to the mysterious deep nets. However, this began to change as gigantic deep nets trained on massive amounts of data began to outperform standard algorithms. “It could end out the same way.”

Meanwhile, Knyazev sees numerous areas where he can develop. For example, GHN-2 can only be trained to predict parameters for a certain task, such as classifying CIFAR-10 or ImageNet images, but not both. He envisions training graph hypernetworks on a wider range of designs and tasks in the future (image recognition, speech recognition and natural language processing, for instance). The prediction can then be tailored to the target architecture as well as the specific task at hand.
If these hypernetworks become popular, the creation and development of revolutionary deep neural networks will no longer be limited to organisations with significant finances and access to large amounts of data. Anyone could participate in the game. Knyazev recognises the potential to “democratise deep learning,” seeing it as a long-term goal.
However, if hypernetworks like GHN-2 become the usual way for optimising neural networks, Velikovi points out a potential major issue. “You have a neural network — effectively a black box — anticipating the parameters of another neural network,” he explained. So you have no way of explaining [it] when it makes a mistake.”
Of course, neural networks are already largely in this position. “I wouldn’t call that a flaw,” Velikovi stated. “I’d call that a cautionary sign.”
Kipf, on the other hand, sees a silver lining. “I was more enthusiastic about it because of something else.” GHN-2 demonstrates the potential of graph neural networks to detect patterns in complex data.
Deep neural networks typically look for patterns in photos, text, or audio signals, which are all very structured sorts of data. GHN-2 looks for patterns in the graphs of neural network topologies that are fully random. “That’s a lot of information.”
GHN-2, on the other hand, can generalise, which means it can produce reasonable parameter predictions for unknown and even out-of-distribution network structures. “This work shows us that many patterns in different architectures are comparable in some way, and a model may learn how to transfer knowledge from one design to another,” Kipf said. “That’s something that could lead to a new neural network theory.”
If this is the case, it could lead to a better understanding of those mysterious black boxes.



