
Fake news is one of the most serious problems confronting the modern world. The COVID-19 epidemic has exacerbated the situation.
Taking the lead, three former students of Jadavpur University in Kolkata, Sourya Dipta Das (currently working as a Research Engineer at SHL India), Ayan Basak (working as a data scientist at Snapdeal), and Saikat Dutta (working as a data scientist at LG Ads Solutions), developed an AI model for fake news detection that is highly accurate. Their research was just published in the Neurocomputing journal. Analytics India Magazine reached out to the trio to learn more about their AI model’s intricacies.
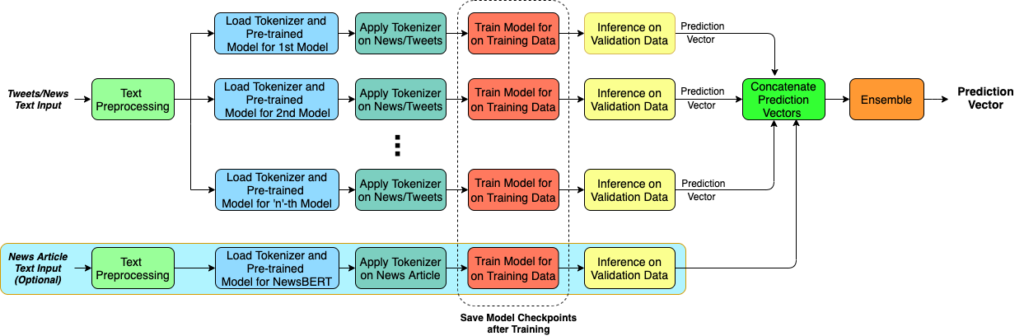
Architecture of the model
The model is made up of seven basic components:
- Text Preprocessing
- Tokenisation
- Backbone Model Architectures
- Ensemble
- Statistical Feature Fusion Network
- Predictive Uncertainty Estimation Model
- Heuristic Post Processing
1. Text Preprocessing
A large portion of social media content, such as tweets, is written in informal language and contains information such as usernames, URLs, and emoticons. Before feeding the data into the ensemble model, the team filtered out such attributes as a basic preprocessing step.
2. Tokenisation
Each sentence is broken down into tokens before being fed into a model during tokenisation. Because each model needs tokens to be constructed in a specific way, including the presence of model-specific special tokens, the team has utilised a number of tokenization algorithms based on the pre-trained model used. Each model has a vocabulary that is associated with its tokeniser and has been trained on a huge corpus of data. Each model uses the tokenisation technique with its matching vocabulary on news data during training.
3. Backbone Model Architectures
As backbone models for text classification, the team used a range of pre-trained language models. “For each model, an additional fully connected layer is added to its respective encoder sub-network to obtain prediction probabilities for each class- ‘real’ and ‘fake’ as a prediction vector. Pre-trained weights for each model are fine-tuned using the tokenized training data. The same tokeniser is used to tokenise the test data and the fine-tuned model checkpoint is used to obtain predictions during inference,” Dutta said.
4. Ensemble
To arrive at their final classification conclusion, the team employed the model prediction vectors derived through inference on the news titles for the various models, i.e. “genuine” or “false.” The goal of deploying an ensemble of fine-tuned pretrained language models is to take advantage of knowledge collected by the models from the dataset they were trained on.
However, they obtained an additional prediction vector using NewsBERT on the news body in the FakeNewsNet dataset, which is also attached to the current feature set. All of the features in this article are derived from raw text data. An ensemble technique can be effective for a collection of similarly well-performing models to balance the limits of a single model.
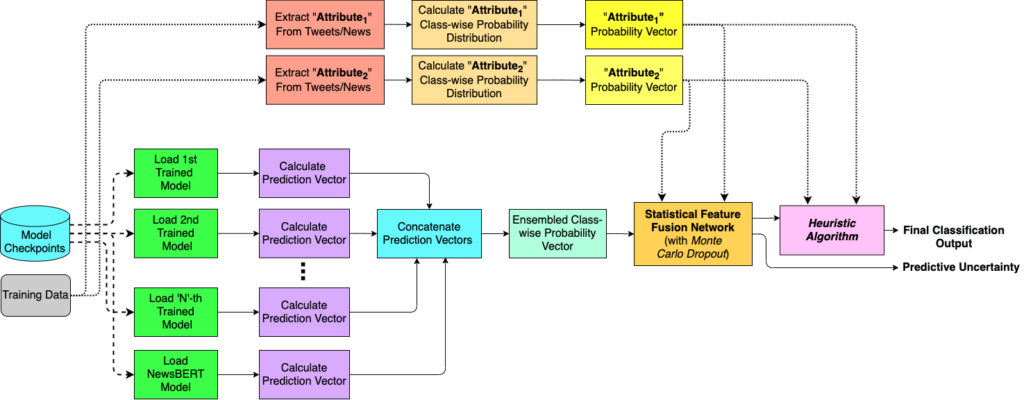
5. Statistical Feature Fusion Network
“Our basic intuition behind using statistical features is that meta-attributes like username handles, URL domains, news source, news author, etc. are very important aspects of a news item and they can convey reliable information regarding the genuineness of such items. We have tried to incorporate the effect of these attributes along with our original ensemble model predictions,” Dutta said.
They came up with probability values for each of the features (for example, the likelihood of a username handle or URL domain indicating a fake news item) and incorporated them to our feature set. Additionally, the team computed these probability values using information from the training set regarding the frequency of each class for each of these features, and discovered that Soft-voting worked better than Hard-voting. Soft-voting prediction vectors are thus taken into consideration in the post-processing step.
6. Predictive Uncertainty Estimation Model
For uncertainty estimation of false news categorization, the researchers created a Statistical Feature Fusion Network (SFFN), which is an approximation Bayesian neural network. For Bayesian interpretation, the scientists used a Monte Carlo Dropout (MCDropout) layer between hidden layers of the feature fusion network.
Both during training and inference, the Monte Carlo (MC) dropout is used. As a result, the model does not generate the same output every time the same data point is inferred. They were able to create random predictions using the MC dropout, which may be regarded as samples from a probability distribution. They obtained the prediction vector as well as the uncertainty value using this model.
7. Heuristic Post-Processing
They supplemented the basic framework with a heuristic technique that took into account the statistical attributes’ impact. This method works effectively with data that includes attributes such as URL domains, username handles, news source, and so on. They used ensemble model predictions for texts that lacked these characteristics. They were able to add meaningful features to the current feature set because to these traits. They created new training, validation, and test feature sets by combining ensemble model outputs with class-wise probability vectors, as well as probability values derived from statistical features in the training data.
“We use a novel heuristic algorithm on this resulting feature set to obtain our final class predictions. The intuition behind using a heuristic approach taking the statistical features into account is that if a particular feature can by itself be a strong predictor for a particular class, and that particular class is predicted whenever the value of a feature is greater than a particular threshold, a significant number of incorrect predictions obtained using the previous steps can be ‘corrected’ back,” said Dutta.
Challenges

Language models, according to Basak, were vital in the development of the model. Statistical ideas such as approximate Bayesian Inference have also been applied to do uncertainty estimation for false news items. TensorFlow 2.0 and scikit-learn were used to create the model, which was built in Python.
“We have developed hand-engineered statistical features using attributes like author name, URL domain, etc, and it was quite challenging to devise a strategy to fuse these features with the model predictions and make a prediction. The uncertainty estimation in the case of fake news classification was also very difficult. Finally, ensuring that our framework is robust and unaffected by variations in the type of news items was a very big challenge,” said Basak.
The team employed data augmentation with an oversampling technique to address the data imbalance problem (KMeans-SMOTE). They combined the hand-engineered statistical features with the model predictions using the Statistical Feature Fusion Network (SFFN) sub-model.
“We have also used transfer learning using a number of different pre-trained language models trained on a large data corpus. This ensured our final model is robust and also has a diverse knowledge base from different sources,” said Das.



